Aristide Torrelli, fotografo fine art
Il mondo attraverso i miei obiettivi: luce, tecnica e visione

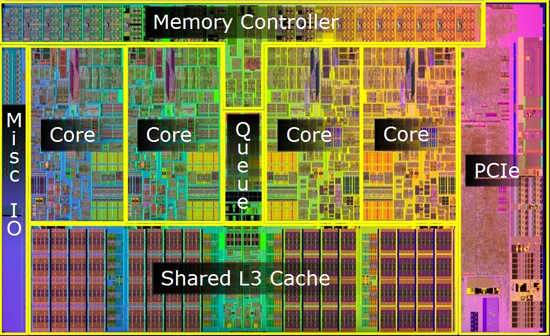
CPU AMD Athlon X4 950 Quad Core 3,8 GHz (immagine reperita in rete)
Aristide Torrelli, fotografo fine art
Il mondo attraverso i miei obiettivi: luce, tecnica e visione
Fate click sul link. Verrete portati su Amazon. Tutti gli acquisti che fate su Amazon tramite il mio sito mi permetteranno di guadagnare qualcosa e continuare l'opera di divulgazione della fotografia in generale e quella digitale in particolare.
Ogni volta che esce una nuova fotocamera si pone l’accento sul nuovo processore che ha a bordo. Più veloce, più potente, più … insomma, avete capito.
Ricordo bene gli anni ’90 e i primi anni 2000, la corsa dei microprocessori a prestazioni sempre più spinte, veloci, la legge di Moore (il raddoppio dei transistor integrati nel chip ogni 18 mesi) verificata. Vi ricordate Intel e AMD con i loro processori? Il mio è a 1,8 GHz, il mio a 2, il mio a 2,2… si ma il mio ha doppio core… ah si? Il mio ha quattro core. Più grosso e più veloce sembrava la regola. Oggi tuttavia sembra che la corsa all’aumento del clock si sia fermata. E’ da qualche anno che le CPU girano tra i 3 e i 4 GHz di clock massimo e qualcuno si chiede: ”E’ finita la corsa?”
No, non è finita, è solo cambiata. Oggi non si insegue più la sola velocità di clock per aumentare le prestazioni ma molte altre cose. E per capire bene cosa questo significa per le nostre fotocamere, andiamo a dare un’occhiata. Tenete presente che quel che segue è relativo alle CPU general purpose, quelle dei computer. Le fotocamere hanno delle CPU specializzate, perciò sono simili ma non uguali a quelle dei computer. Ricordate che molte operazioni su immagini si fanno con dei DSP (digital signal processor) o con PLA (programmable logic array) che si specializzano nel fare una cosa sola, che so, applicare una maschera di contrasto a un file jpg. Praticamente è un microprocessore che sa fare una cosa sola ma molto velocemente.
Però una cpu è una cpu e esegue del codice e quel che segue spiega come fare a velocizzare una cpu senza aumentare il clock.
Pipelining
Il pipelining divide le fasi di esecuzione in fasi più piccole, consentendo velocità di clock più elevate.
Per capire come funziona, immagina una catena umana che si passa dei secchi d’acqua. Se ci sono poche persone nella catena, ogni persona deve camminare avanti e indietro per afferrare un secchio dalla persona precedente e consegnarlo a quella successivo. Il camminare avanti e indietro rende ogni fase più lunga, che nel linguaggio del processore viene chiamata latenza. Rendere più semplice ogni fase consente una maggiore velocità di clock. Immagina di aggiungere un numero sufficiente di persone alla squadra in modo che una persona possa afferrare un secchio e consegnarlo alla persona successiva senza dover nemmeno fare un passo.
Il compromesso è che se uno di questi stadi si blocca, lo fanno tutti. Quindi, se una fase è in attesa di un secchio, tutti prima devono fare una pausa.
Super scalare
I processori più moderni hanno un numero di pipeline in grado di eseguire istruzioni in parallelo. In genere sono ottimizzati per determinati tipi di attività, come matematica intera o matematica in virgola mobile, unità logica e aritmetica, caricamento e memorizzazione. L'emissione di istruzioni in parallelo è fondamentalmente come avere più persone con i secchi che lavorano insieme, ma c'è un limite al numero di istruzioni che il processore può emettere allo stesso tempo. Avere un sacco di unità di esecuzione è una cosa, mantenerle occupate è un'altra. Lo scheduler deve determinare il modo più efficiente per schedulare le istruzioni di diversi tipi. Deve schedularle per recuperare i dati di cui avranno bisogno le istruzioni, tenendo conto di quanto tempo ci vorrà per caricare i dati dalla memoria nelle cache e dalle cache nei registri appropriati. Le pipeline che non stanno eseguendo le istruzioni consumano solo energia e, man mano che la velocità di emissione delle istruzioni dei processori aumenta, è anche più difficile per lo scheduler mantenere le unità occupate. A causa di ciò, il numero di emissione dei processori tende a un numero tra sei e otto.
Decodifica Istruzione
I compilatori generano istruzioni basate su un'architettura dell'insieme di istruzioni. Poiché si tratta di una specifica che si estende su una varietà di processori, ciascuna versione del processore deve decodificare le istruzioni del compilatore nelle istruzioni native del processore. In alcune architetture di processore, ciascuna pipeline ha un decodificatore e alcune hanno un solo decodificatore che salva le istruzioni decodificate in una cache di tracciamento. Con una cache di tracciamento, il decodificatore non deve decodificare le istruzioni ogni volta che le incontra, solo la prima volta. Ciò può comportare un significativo miglioramento dell'efficienza e delle prestazioni nei programmi che eseguono ripetutamente le stesse sequenze di istruzioni su un ampio set di dati, ad esempio.
Esecuzione fuori sequenza
Lo scheduler delle istruzioni nel processore cerca di mantenere più pipeline e unità di esecuzione occupato possibile. Per fare questo, cercherà di capire quali istruzioni dipendono dalle uscite di altre istruzioni e le riordinerà per mantenere il processore il più occupato possibile. Il processore tenterà anche di prevedere quali dati saranno necessari alle istruzioni per completare l'esecuzione e caricherà i dati dalla memoria per renderli disponibili quando l'istruzione è pronta per essere eseguita. Se la sua previsione è corretta, il processore rimane più occupato, in caso contrario subisce una penalizzazione (perdita di tempo) per la predizione scorretta.
SIMD
Single Instruction, Multiple Data o SIMD è un modo per impacchettare più operazioni in una singola istruzione. Conosciuto anche come calcolo vettoriale, questa è una tecnica comune nei supercomputer che è ormai onnipresente nei personal computer. Ogni vettore contiene più parti di dati e il processore può eseguire quella istruzione su tutti i dati allo stesso tempo. Un esempio è l’aumento di luminosità di tutti i valori di colore di un pixel in Photoshop di un certo valore intero. Questo metodo implica il riempimento dei valori iniziali in un vettore e l'aggiunta di quel numero a ciascun pixel in un altro vettore e l'emissione di un'istruzione di somma vettoriale. Quindi tutti i valori in ogni vettore sono sommati con un'istruzione. Ciò richiede una parallelizzazione esplicita quando si scrive il programma, e alcuni carichi di lavoro sono più suscettibili a un parallelismo di questo tipo rispetto ad altri. Le applicazioni di editing di foto e video si prestano piuttosto bene a questo tipo di parallelismo a livello di istruzioni. E’ qui che gli ingegneri delle case costruttrici di fotocamere danno il loro meglio perché essendo le loro CPU specifiche per il tipo di lavoro, possono parallelizzare le attività più semplicemente che in una CPU di uso generico.
Multithreading simultanei
I thread sono simili ai processi, tranne per il fatto che condividono il loro heap con il processo principale e l'uno con l'altro. Mantengono comunque il proprio contatore di programma e stack. Per coloro che non hanno familiarità con questi termini, l'heap è dove un programma conserva i suoi dati, e lo stack è dove tiene traccia delle istruzioni. Un processore con multithreading simultaneo (noto anche come HyperThreading in linguaggio Intel) può schedulare le istruzioni da più thread contemporaneamente. Ciò offre allo scheduler una maggiore flessibilità per il rilascio di istruzioni in parallelo, il che porta a tenere occupati molti delle sue pipeline.
Registri
I registri sono dove le unità di esecuzione del processore prendono i loro dati e li salvano quando eseguono le istruzioni. Se i dati di cui ha bisogno un'unità di esecuzione è nei registri (dove si aspetta di trovarlo mentre sta eseguendo le sue istruzioni), allora funziona senza impedimenti. Se i dati non ci sono ancora, l'unità di esecuzione deve attendere per questo, che nella maggior parte dei casi blocca l'intera pipeline. I processori moderni hanno una logica dedicata a prevedere di quali dati il processore avrà bisogno e quando, con l'intenzione di caricarli nei registri prima che il processore ne abbia bisogno.
Cache
I dischi rigidi hanno una latenza molto grande per l'accesso, il che significa che, dal momento in cui il processore principale invia una richiesta per alcuni dati, al momento in cui i dati arrivano, passa molto tempo. Perciò i processori caricano programmi e dati nella memoria principale ed eseguono da lì. La memoria principale ha ancora una latenza piuttosto elevata, in particolare perché normalmente funziona a velocità di clock che possono essere 1/10 della velocità di clock del processore. Per mitigare questa latenza, i processori hanno cache ad alta velocità sui loro circuiti. Alcuni hanno un livello di cache, altri ne hanno due o tre. Di solito hanno una piccola cache di primo livello che il processore usa per caricare i dati nei registri, una cache di secondo livello più grande ma non altrettanto veloce e, in alcuni casi, una cache di terzo livello ancora più grande. In alcuni processori, tutti i livelli di cache sono specifici per un core, mentre in altri la cache di terzo livello potrebbe essere condivisa tra i core in un singolo chip, mentre le cache di primo e secondo livello sono dedicate a ciascun core.
Core multipli
Più core è praticamente lo stesso di più processori, ma sullo stesso die (sottile piastrina di materiale semiconduttore sulla quale è stato realizzato il circuito elettronico del circuito integrato.). Questo approccio riduce i costi di produzione in generale, dal momento che un singolo chip con sei core ha bisogno di un solo chip carrier. Anche le interconnessioni tra processori sullo stesso die sono molto veloci, migliorando ulteriormente le prestazioni parallele.

Velocità di clock
La velocità di clock è un modo ovvio per aumentare le prestazioni di un processore. Più cicli di clock significano più lavoro, ma c'è il contraltare. L'aumento della frequenza aumenta il consumo di energia, che aumenta il calore. Il calore non può superare certi limiti, pena la rottura del chip. A causa di questo limite termico, le velocità di clock non sono aumentate molto. Negli ultimi anni, però, c’è stata una forte spinta verso la riduzione del consumo di energia nei processori, che ha permesso di migliorare ulteriormente le prestazioni.
Nuove tecnologie
Lo sviluppo di modi per ridurre le dimensioni dei processori consente ai produttori di inserire più transistor in una data matrice e consente inoltre velocità di clock più elevate, poiché i transistor più piccoli richiedono correnti più piccole per farli funzionare. Porta anche ad altre difficoltà, perché gli artefatti sui processori oggi sono così piccoli che gli effetti quantici introducono sfide per la produzione. Uno grande è il risultato di come vengono create le tracce sulla superficie di un wafer. Il wafer ha un substrato su di esso, che è sensibile agli acidi, fino a quando non viene riscaldato. Per fare questo, un laser controllato da un motore passo-passo di precisione viene passato sopra una maschera. La maschera funziona come uno stencil in modo tale che il laser stia solo “disegnando” le parti del substrato che devono rimanere. Con le dimensioni degli artefatti coinvolte nella litografia moderna, la diffrazione attraverso la maschera può essere piuttosto significativa, portando i produttori a sviluppare tecniche per controllare il raggio del laser. Ad esempio, AMD ha sviluppato un sistema di litografia ad immersione che mette una piccola goccia di acqua pesante nello spazio tra il laser e la maschera, e dopo un impulso la risucchia di nuovo, per metterla davanti al laser dopo che è stato spostato sul prossimo punto.
Dopo che il laser ha finito, il wafer viene lavato con acido, rimuovendo il substrato non inciso. Quindi lo strato successivo viene depositato a vapore sul wafer e il processo continua con il livello successivo.
Compromessi e innovazione
Come spesso accade, ci sono dei compromessi con tutti questi approcci per migliorare le prestazioni. L'aumento della velocità di clock è caduto in disgrazia a causa del calore e del consumo energetico. L'aggiunta di pipeline può aumentare le prestazioni, ma mantenere le pipeline occupate diventa più difficile quante più pipeline ha il processore. L'aumento della profondità della pipeline consente ai progettisti di aumentare la velocità di clock, ma aumenta anche le penalità per i caching mancati e per le previsioni errate su quali dati caricare e quando. Tutto ciò che aggiunge logica al die di un processore aumenta il suo costo in due modi. Uno è che con un die più grande e una dimensione di wafer costante, c'è spazio per meno parti nella stessa area di superficie. Un altro è che anche i wafer moderni hanno difetti e la probabilità di avere un difetto in una data parte di un wafer è praticamente costante. Anche se è basso, è sufficiente a causare difetti fatali in alcuni dei die. Dal momento che la probabilità di avere un difetto nel wafer è costante, un die più grande ha una maggiore possibilità di includere un punto con un difetto. Se il difetto si trova in un blocco cache, è possibile aggirare il problema rimappando il blocco cache. Le celle di memoria sono relativamente semplici e relativamente piccole in termini di area del die, e quindi aggiungono relativamente poco al costo di produzione, quindi è fattibile progettare cache extra in un processore per aumentare i rendimenti in questo modo. Con la logica tuttavia, un difetto tende a presentarsi nel processore. Quando un wafer esce dalla linea, viene tagliato in stampi e ogni die viene testato alla velocità di clock prevista pre il chip, con un margine per garantire l'affidabilità. Se fallisce, viene testato al prossimo livello inferiore di velocità di clock, fino a quando non passa. Quando passa, viene messo in un contenitore in base alla velocità a cui è affidabile. Questo processo è chiamato binning. Il personale di marketing e gestione aziendale capisce quale sia la migliore distribuzione dei processori per massimizzare i profitti, dal momento che un processore può essere contrassegnato per qualsiasi velocità di clock inferiore alla sua valutazione, ma non superiore. La maggior parte delle vendite proviene dai contenitori inferiori, ma i premi che le persone sono disposte a pagare per i processori con maggiore clock portano a margini di profitto elevati. Questo è il motivo per cui alcuni processori della stessa linea overclockano meglio di altri, e anche perché i processori sbloccati hanno un prezzo molto alto.
Per migliorare le prestazioni e il consumo energetico, i progettisti di processori devono bilanciare questi metodi e sviluppare nuovi metodi per continuare a migliorare le prestazioni. Per un po’, sembrò che la velocità di clock fosse la risposta, fino a che il Pentium 4 non colpì il limite termico. Ora il consumo di energia sta diventando un problema sempre più importante e i progettisti di processori stanno cercando di estrarre il massimo di prestazioni per watt possibile. I data center sono enormi consumatori di energia, in particolare quelli di grandi dimensioni con migliaia di processori, quindi ridurre al minimo il consumo di energia può fare un'enorme differenza. L'ascesa del tablet come piattaforma di elaborazione continua anche a guidare la crescente domanda di processori che consumano meno energia, ma c'è una richiesta continua di maggiori prestazioni. Per la maggior parte degli utenti, un moderno processore Core i7 con due core ha più prestazioni di quante ne avremo mai bisogno. Del resto, anche il processore Core i3 in un entry level Surface 3 Pro o un processore ARM dual-core, come quello nell'iPad Air, è più che sufficiente per la maggior parte degli utenti di computer occasionali. Le prestazioni single-threading sono ancora importanti per alcune applicazioni, in particolare i giochi e applicazioni di elaborazione simili che non si parallelizzano facilmente. I carichi di lavoro dei server in genere coinvolgono più carichi di lavoro paralleli, come server web e database, quindi i processori realizzati per i server generalmente riducono la velocità di clock a favore di core aggiuntivi e cache on-die più grandi.
Il video editing e la gradazione del colore si adattano bene, rendendo i processori del server una buona scelta per le workstation di editing video. Anche molti renderizzatori 3D fanno buon uso di più core. Alcune di queste applicazioni si adattano bene anche al GPU computing, a causa del loro parallelismo. Mentre le velocità di clock stanno aumentando molto lentamente negli ultimi tempi, le prestazioni del processore continuano ad aumentare, anche se non con i salti mortali visti alla fine degli anni '90 e all'inizio del 2000. Ridurre drasticamente il consumo energetico è diventato una priorità e le tecniche di gestione dell'alimentazione sono diventate estremamente sofisticate, consentendo ai processori di spegnere parti del processore quando non sono in uso e di regolare la velocità del clock in risposta al carico di lavoro e alla temperatura. Per la maggior parte delle applicazioni, l'aggiunta di core offre pochi o nessun vantaggio. Le applicazioni che non si parallelizzano bene non beneficiano di core aggiuntivi, e anche per le applicazioni che funzionano parallelamente, richiedono notevoli capacità ingegneristiche per sfruttarli e pochi hanno esperienza nello sviluppo parallelo o distribuito delle applicazioni. Oltre al muro termico, il mercato dei personal computer sta cedendo il passo al mercato della telefonia mobile, dove dominano tablet e telefoni cellulari. Dal momento che anche un processore entry level è ora più che sufficiente per gli utenti di computer occasionali, c'è sempre meno incentivo per i progetti di processori a prestazioni elevatissime. Alcune società stanno costruendo centri dati con processori ARM per mantenere basso il consumo energetico. Per la maggior parte nel mercato attuale, i mercati principali per i modelli di processore di fascia più alta sono limitati ai giocatori e ai creatori di contenuti dedicati. Le stesse persone in cerca di processori di fascia alta preferiscono anche le GPU di fascia alta per il computing e per il rendering 3D in tempo reale. Le velocità di clock probabilmente non saliranno mai più come durante la corsa tra l'Athlon e il Pentium4, ma continueremo a vedere miglioramenti nelle prestazioni. Non sarà così facile da quantificare, proprio come la difficoltà nel determinare la qualità dell'immagine che un sensore è in grado di offrire basandosi solo sul suo numero di megapixel.
Fate click sul link. Verrete portati su Amazon. Tutti gli acquisti che fate su Amazon tramite il mio sito mi permetteranno di guadagnare qualcosa e continuare l'opera di divulgazione della fotografia in generale e quella digitale in particolare.
Aiutatemi ad aiutarvi
Vi è piaciuto il tutorial? Lo avete trovato utile? Se il mio sito è per voi utile come un libro che avreste dovuto comprare o un workshop che avreste dovuto frequentare, pagando, allora permettetemi di continuare ad aiutare tutti. Se non lo avete ancora fatto, fatelo adesso. E' bello che ci siano persone come voi che mi permettono di continuare ad aggiungere conoscenza al sito. Grazie.

Politica per la privacy e i cookies del sito
©2006 - Aristide Torrelli - PIva 15633041007